6 月 7 日,由卓普云与 DigitalOcean 联合主办的“DigitalOcean 开发者沙龙”在北京圆满落幕。活动以“如何优雅的玩转 AIGC——训练、推理、知识库的那些事儿”为主题,邀请了多位 AI 行业内的技术专家。在本场活动中,卓普云科技解决方案架构师兼DigitalOcean Cloud Solutions Expert 丁可,以《从选型到架构,构建AI训练和推理算力》为主题,详细介绍了其作为云服务提供商,如何助力企业构建和优化AI训练及推理的算力基础设施。
以下为演讲实录:
我今天的分享内容,对在座的各位应该都会有些帮助,因为它比较通用。当前GPU和AI算力,特别是考虑到中美之间众所周知的原因,我们主要的GPU资源都来自于海外。因此,无论你是从事AI相关工作,需要用到GPU的,都可以听听我们这边的分享,包括我们如何设计云服务来应对训练类和推理类的需求,希望能给大家一些启发和灵感。

不敢说我们的方案一定是完美的,但至少我们这边在云服务设计时,不光考虑了性能和最先进的技术,也充分考虑了成本因素。GPU是所有AI算力中最昂贵的一部分,许多初创公司,尽管其核心业务可能主要在AWS上,但在我们平台上的开销却可能占到其总开销的75%以上,足见我们平台对其业务的重要性。这主要是因为其核心业务依赖于GPU。虽然其他资源也很重要,甚至非常核心,但CPU资源的成本很难大幅度压缩。
对于初创公司而言,我们在初期会更多地考虑成本效益。因此,我们的云服务在设计时,除了性能和技术领先性,还尤其注重经济性。相比AWS等大型云服务商,我们的成本可以降低一半以上。这对于大多数初创公司来说非常有吸引力。
DigitalOcean是谁?
首先先介绍一下我们的产品与服务,这样也方便后续探讨更多细节。DigitalOcean 是一家成立于 2012 年的云平台,是云服务行业的早期参与者之一。DigitalOcean 致力于提供一个简约且完整的云平台,并且成本可控,帮助团队高效工作并取得最佳成果。
可以看到这张图,这张图展示了DigitalOcean在过去十几年中的发展历程以及其发布的主要的产品服务。
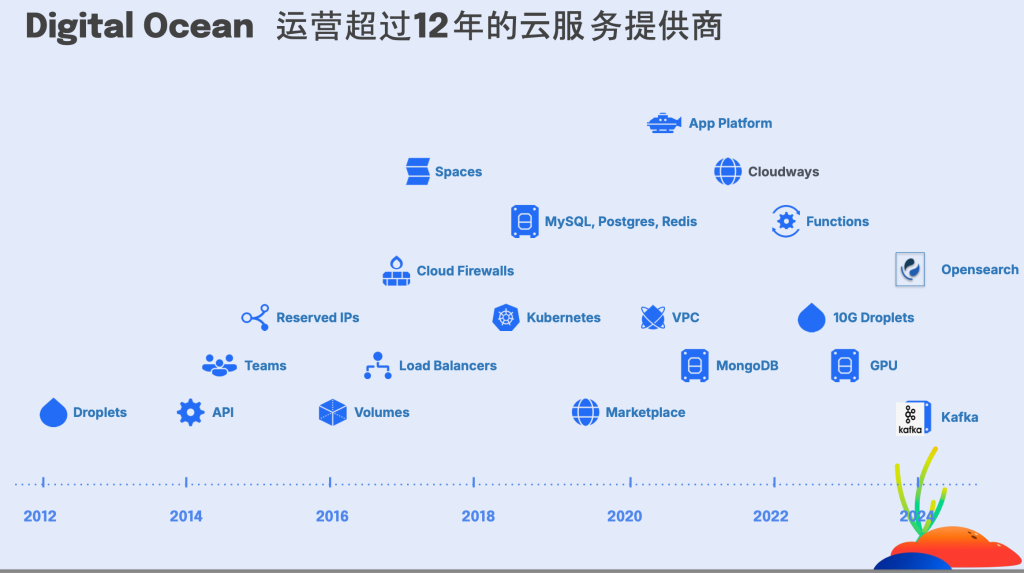
我们从2012年开始运营,逐步推出了Droplets(虚拟机)、API、Reserved IPs、Teams、Spaces(对象存储)、Cloud Firewalls、Load Balancers(负载均衡)、Volumes(块存储)、App Platform、Cloudways、托管数据库(如MySQL, Postgres, Redis, MongoDB, OpenSearch)、Kubernetes、VPC、Marketplace以及最新的GPU服务和Kafka等。这些都是我们逐步完善的产品线。
2023年,Paperspace被DigitalOcean收购。Paperspace是一个专注于GPU云服务的平台,其加入使得我们将公有云的运营经验应用于GPU云服务。Paperspace的使命是成为“为未来构建的云平台”,为成千上万的个人、初创公司和企业提供下一代应用的基础设施。

2024年,新的首席产品和技术官Bratin Saha加入了我们。Bratin Saha在加入DigitalOcean之前,曾是AWS人工智能、机器学习及数据基础设施的副总裁兼总经理。他领导了AWS历史上增长最快的AI/ML服务业务,并在计算机科学、数据科学、分布式系统、云计算、AI和机器学习领域拥有20多年的经验,持有15项已获批的专利。他的加入无疑为DigitalOcean在AI/ML领域的发展注入了强大的动力。在他的领导下,我们不仅提供千卡集群,由于Bratin 和 DO 的技术团队具备万卡集群的构建与运营经验,所以 DO 也能根据客户需求定制集群规模。
为什么那么多出海企业、创业公司选择DigitalOcean?
相较于大型云服务商,我们的优势在于简单、价格实惠和可靠性。例如,大型云服务商的服务比较复杂,需要比较专业技能的人员才能维护好,一位工程师初次配置一套可以被访问的云主机服务器就用了两天,需要配置各种 IAM 权限、VPC 网关、路由表和安全组。而在DigitalOcean的平台上,包含注册账号、阅读文档的过程,只花费几个小时就能上线一个可被访问的云主机服务器。这得益于 DO 简洁的产品设计。此外,我们的计费模式更加简洁透明,账单通常只有一两页纸,而超大规模云则复杂的多,有些高端用户甚至必须通过数据分析工具才能很好的分析账单。我们的目标是在保证高可靠性的前提下降低成本,确保服务稳定性和高可用性。我们的核心服务SLA要求达到99.99%,确保服务的高可靠性。

这张图总结了选择DigitalOcean作为AI算力平台的几大理由:
- AI/ML加速:我们的云服务专注于AI和ML工作负载的加速。
- 简单易用:我们致力于提供简化、直观的用户体验。
- 高性能GPU:提供高性能的GPU资源。
- 价格透明:我们的定价模型清晰透明,没有隐藏费用。并且产品的定价比 AWS、谷歌云服务等一线大厂更加实惠。
- 全球基础设施:拥有全球分布的数据中心,提供强大的基础设施支持。
- 卓越支持:提供24/7的客户支持。
- 社区和生态系统:拥有活跃的开发者社区和丰富的生态系统。
这些都是我们之所以能吸引全球 60 万企业的原因。
DigitalOcean 如何构建高效、可靠的 AI 训练/推理解决方案?
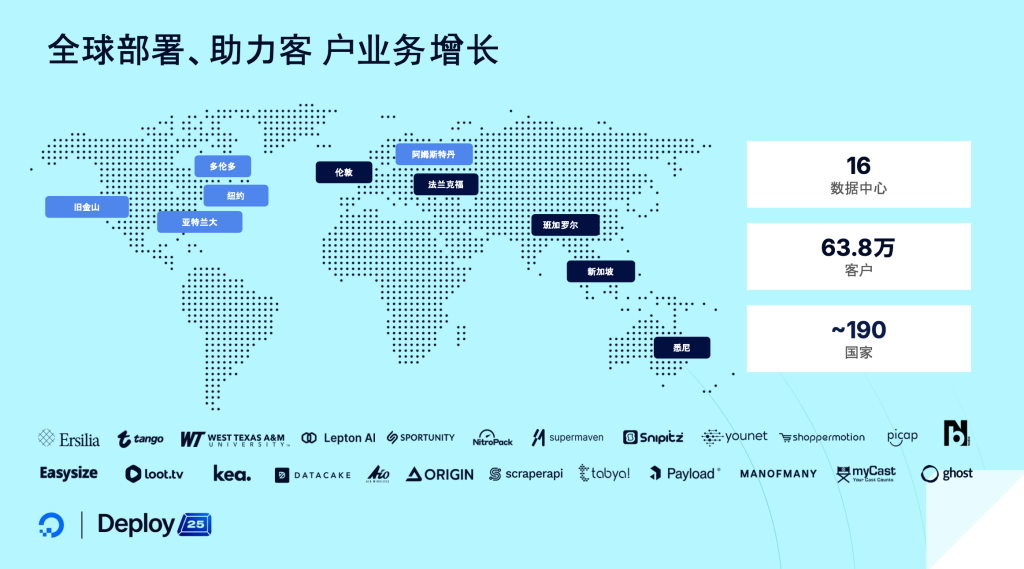
在全球部署方面,我们没有在中国设立区域(region),因此我们的服务主要面向出海类客户。如果你有海外业务需要拓展,并且需要GPU资源,或者由于国内高端算力资源(如H200、B200、B300)难以获取,那么你可以通过我们的平台在海外进行训练或使用资源。此外,如果数据源也在海外,也同样可以直接利用我们的资源来进行高性能低成本的 AI 训练或推理。图中浅蓝色部分表示我们提供GPU的数据中心,目前我们在欧洲和美国设有五个区域提供GPU 云服务,亚太地区暂时仅提供传统的CPU云计算资源。
与一线云厂商相比,我们的优势在于成本更低且更可控,同时可靠性并未显著下降。对于同样提供GPU算力的小型或中型竞争对手,我们提供的是一站式完整能力的服务。我们已经有十几年的经验,尤其是在公有云运营经验方面。随着GPU的兴起,我们将这一能力整合到了我们的云平台中。
构建一个完整的应用服务器、负载均衡器、存储以及GPU的业务可以在我们的平台上得到全面支持,而不是局限于单一服务或容器。这减少了跨云部署的需求,从而提升了可靠性和隐私保护。我们还提供了包括计算、虚拟机、对象存储在内的多种服务,特别是针对训练所需的高性能并行文件系统。如下图所示。

DigitalOcean作为 AI/ML工作负载的解决方案,可以提供多种层面的技术资源,包括:
- 计算服务 (Compute):提供高性能GPU和CPU实例,用于训练和推理。
- 存储服务 (Storage):提供对象存储、块存储等多种存储选项,满足不同数据存储需求。
- 网络服务 (Networking):提供负载均衡、VPC等网络服务,确保数据传输效率和安全性。
- 数据库服务 (Database):提供多种托管数据库服务,如MySQL、PostgreSQL、MongoDB等。
- 容器和编排 (Containers & Orchestration):提供托管Kubernetes服务(DOKS),简化容器化应用的部署和管理。
- 开发工具 (Developer Tools):提供API、CLI、Terraform等工具,方便开发者进行自动化部署和管理。
- 管理和监控 (Management & Monitoring):提供监控、日志等服务,帮助用户管理和优化资源。
我们将从硬件到软件,再到各种配套服务,提供一个完整的AI/ML基础设施堆栈。同时,完全不像其他云平台那么复杂,DigitalOcean 简单易用的产品特性,可以让使用者在很低的学习门槛下,快速地构建自己的 AI 产品。

2025年,许多用户关心的问题集中在我们的GPU 服务器产品roudmap。目前,H200已经在亚特兰大数据中心上线,7月31日将在纽约上线H200的云主机服务。此外,英伟达的B300和B200新品预计在今年底上线。考虑到AMD GPU的新发布,我们也将其作为性价比更高的选择之一,优化后的AMD MI300X将在 6 月于亚特兰大上线。
在推理类GPU方面,L40S和 RTX A6000 Ada等数据中心级别的卡提供了更好的性价比,尤其适合文生图等应用场景。这些新卡不仅价格更为亲民,而且性能优异,支持最新的技术特性。
我们提供的服务有裸金属和按需的云实例,可以满足不同需求。裸金属服务特别适合那些对硬件控制要求极高的训练任务,而按需云实例则更适合自动化程度较高的推理任务,能够迅速扩展资源以应对需求变化。
最后,我们还提供了Kubernetes 托管服务,类似于亚马逊的EKS或阿里的AKS,让用户能够混合管理CPU和GPU节点。此外, DigitalOcean GenAI 平台可以让用户只需关注agent本身,其他如知识库、文件解析、存储及底层硬件资源的管理均由我们负责。这对于初期验证业务模型非常有用,因为它内置了各种大模型供用户评估。

关于DigitalOcean 裸金属服务器的硬件配置,如下图所示,我们目前提供的裸金属服务器包括H100、H200和MI300X三种机型。
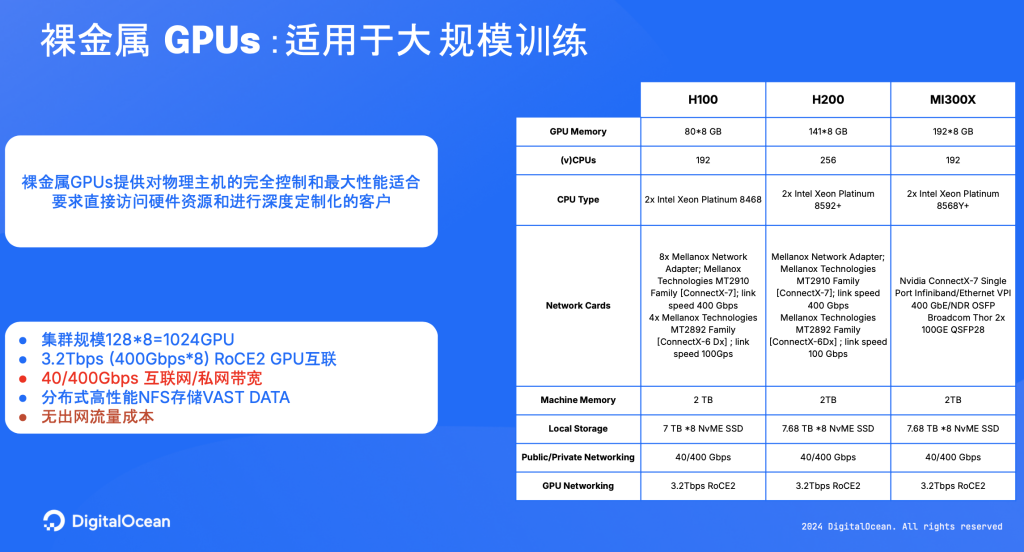
裸金属服务特别适合大规模训练任务,因为这类任务通常需要较大的集群规模。我们的裸金属单集群规模大约为1千张GPU卡,这样的规模有助于降低成本。我们采用了更开放的路线,构建了 RoCE网络进行多机分布式训练,分布式训练时候往往需要一个高速的互联,我们的集群现在可实现行业内顶级的互联标准,3.2Tbps带宽。
我们还集成了分布式的存储解决方案,如VAST DATA,适用于中型高速共享数据集的需求。对于超大型数据集,可以与合作伙伴们一起构建大规模存储解决方案,例如本次参与分享的JuiceFS,在保持性能的同时控制成本。此外,我们的裸金属没有出网流量成本,这对于网络密集型业务来说是一个显著的成本优势。
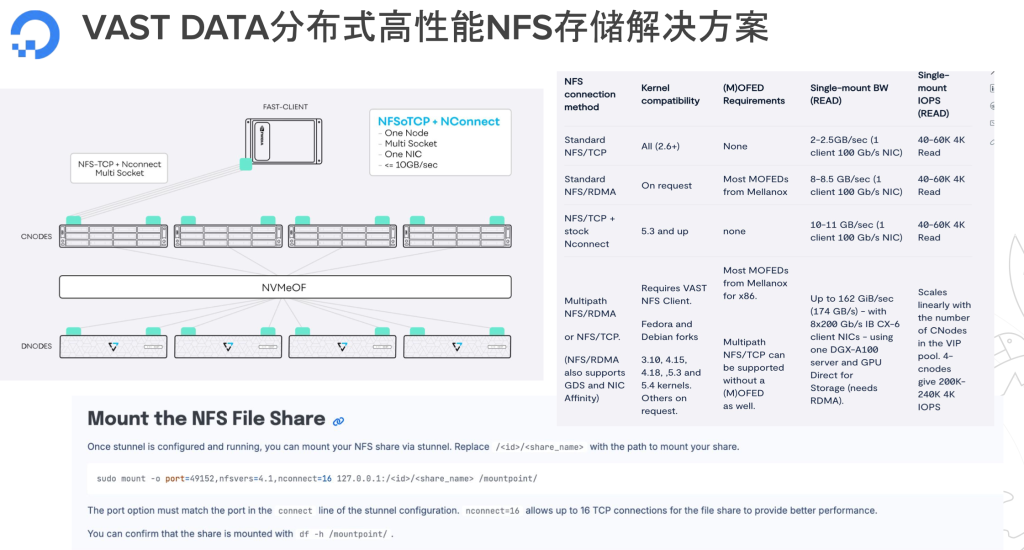
关于高性能存储的解决方案。此前,Juicedata这边也有他们的解决方案。它适合与对象存储结合的超大规模数据集。我们提供的NFS服务专为满足中小规模训练集的需求而设计,成本效益高,特别适合在内网环境中使用。我们与知名的数据存储公司VAST DATA合作,在裸金属服务器级别上提供这一服务。此外,我们的云主机计划于今年七八月份推出托管NFS服务,该服务不仅具备传统NFS的所有功能,还额外提供了多链路、多通道和RDMA支持等高级特性,确保更高的性能和更优的用户体验。通过这次合作,我们将能够更好地支持用户的多样化需求,并为AI训练提供更加稳健的数据存储解决方案。
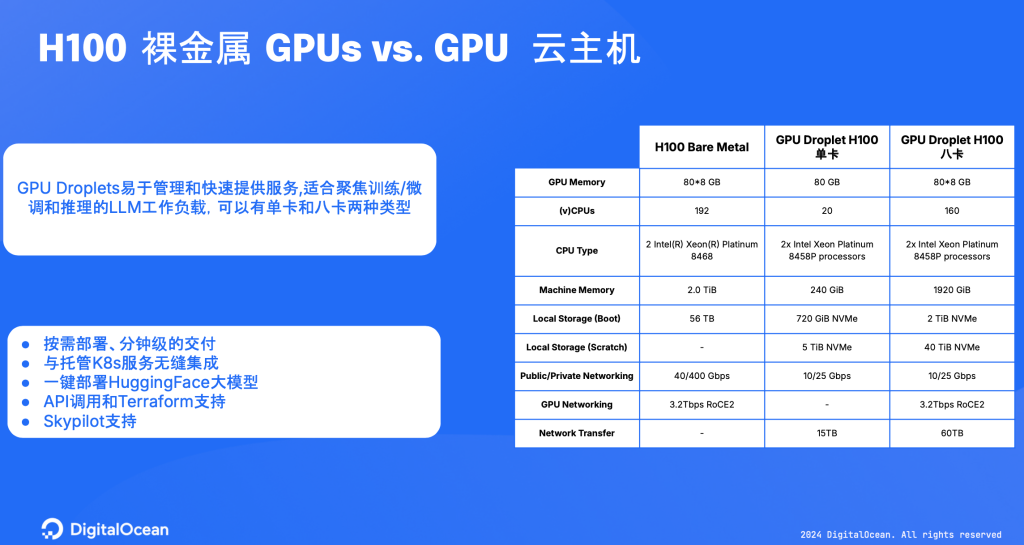
与云主机相比,裸金属服务器在物理规格上提供了更高的带宽。具体来说,我们设定的公网带宽为10Gbps,私网带宽为25Gbps,以符合特定的云平台规格要求。尽管如此,在网络性能方面,两者在使用H100 GPU Droplet 服务器时均能实现3.2Tbps的带宽速度。此外,我们的系统包括三个独立网络:公网、私网以及GPU训练通讯专用网。
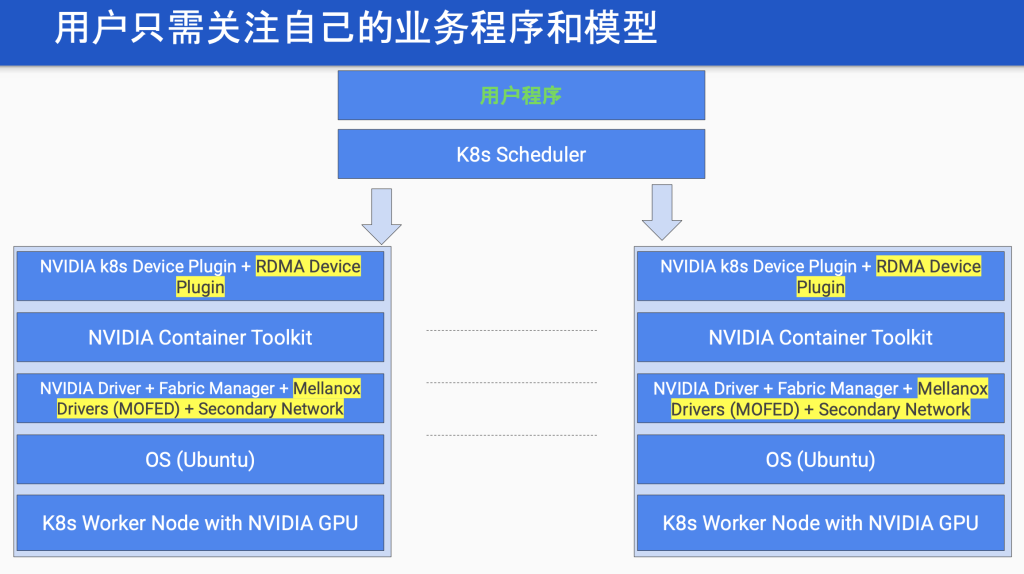
DigitalOcean 提供的云服务中,Kubernetes 托管服务(DOKS)为用户带来了显著优势。我们希望用户只需关注图中绿色字体所示的“用户程序”部分,即专注于部署自己的应用程序。至于下层 NVIDIA 的一系列软件栈,包括 CUDA、GPU 驱动、Fabric Manager、Mellanox 驱动以及支持 RDMA(远程直接内存访问)所需的设备插件等,都由 DigitalOcean 预先打包并提供。
这样做的目的是简化运维。尽管许多数据科学家对这套底层技术有所了解,但很少有人能精通所有技术模型和各种底层驱动的匹配情况,通常他们只熟悉其中一个方面。因此,如果我们能够提供一个打包且定期维护的节点,将大大减轻用户的运维负担。这套软件版本组合经过我们的验证和测试,不易出现问题。如果用户自行维护,则存在各种潜在的兼容性,驱动和Cuda匹配性的风险。因此,我们将所有这些底层组件预置好,让用户能够直接使用。
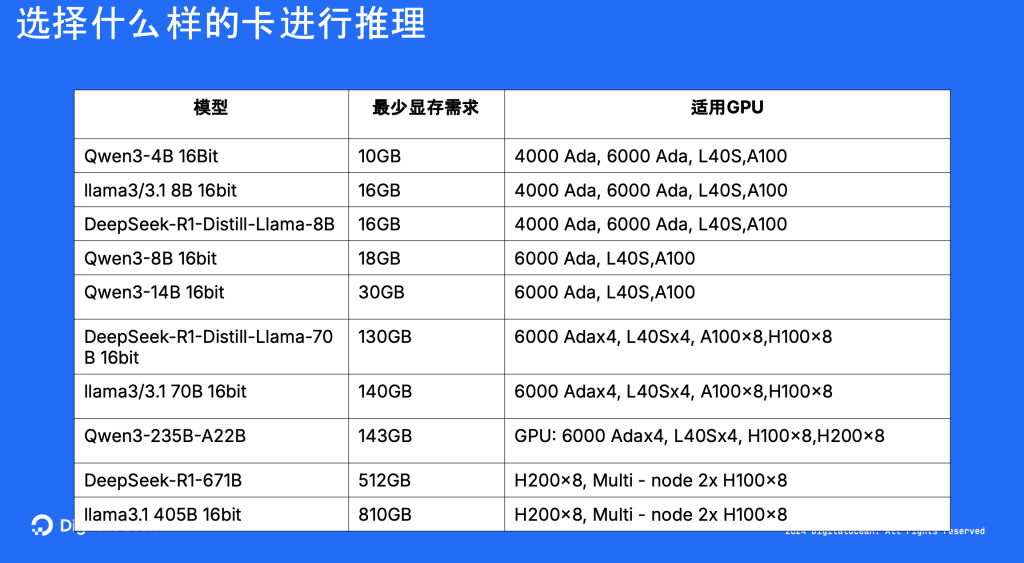
不仅仅是 DigitalOcean 的用户,还有很多做 AI 的团队都会经常考虑一个问题,什么样的模型应该配备什么型号的 GPU。上面这张图就是一个很好的解释。
为了方便 AI 团队的开发,DigitalOcean 云平台还提供了一键部署的能力。DigitalOcean 与 Hugging Face 进行了合作。用户可以在 DigitalOcean 云平台上实现模型的“一键部署”,例如选择部署 DeepSeek R1 的 671B 模型 。系统会自动从 Hugging Face 的模型库中下载模型,并将其部署到 DigitalOcean 的 GPU 服务器上供用户直接使用。平台会提供详细的说明,用户只需按照指引操作即可完成部署,无需进行复杂的配置 。
此外,这种部署方式也解决了用户对数据安全性的担忧。如果担心直接将输入数据放到 DeepSeek 公有云服务可能存在数据安全问题,通过这种自部署方式,数据将保留在用户自己的云环境中 。值得一提的是,这个 API 与 ChatGPT 和 OpenAI 的 API 完全兼容 ,这意味着开发者只需一次开发,从概念验证过渡到生产阶段时,无需修改代码 。Hugging Face 也对模型参数进行了优化,用户无需手动下载或调整,这为需要快速部署的用户提供了极大的便利 。当然,对于特别专业的团队,他们也可以选择自行部署并进行调整,一键部署主要是为 POC(概念验证)和研发阶段的用户提供一个初步的、便捷的选择 。
总结
总而言之,DigitalOcean致力于为AI/ML开发者和企业提供一个简约、高性能、高性价比的云平台。我们不仅提供强大的GPU算力,还提供丰富的配套服务,如对象存储、托管数据库、Kubernetes服务等,帮助用户构建端到端的AI/ML解决方案。
我们希望通过提供这样的服务,让更多的开发者能够专注于模型和应用本身的创新,而无需花费大量精力去管理复杂的基础设施。我们坚信,通过与DigitalOcean的合作,您的AI/ML项目将能够更高效、更经济地运行。如果您对 DigitalOcean 的 GPU 云服务或传统云服务产品感兴趣,希望在 AI 算力资源方面降本增效,欢迎联系我们。



